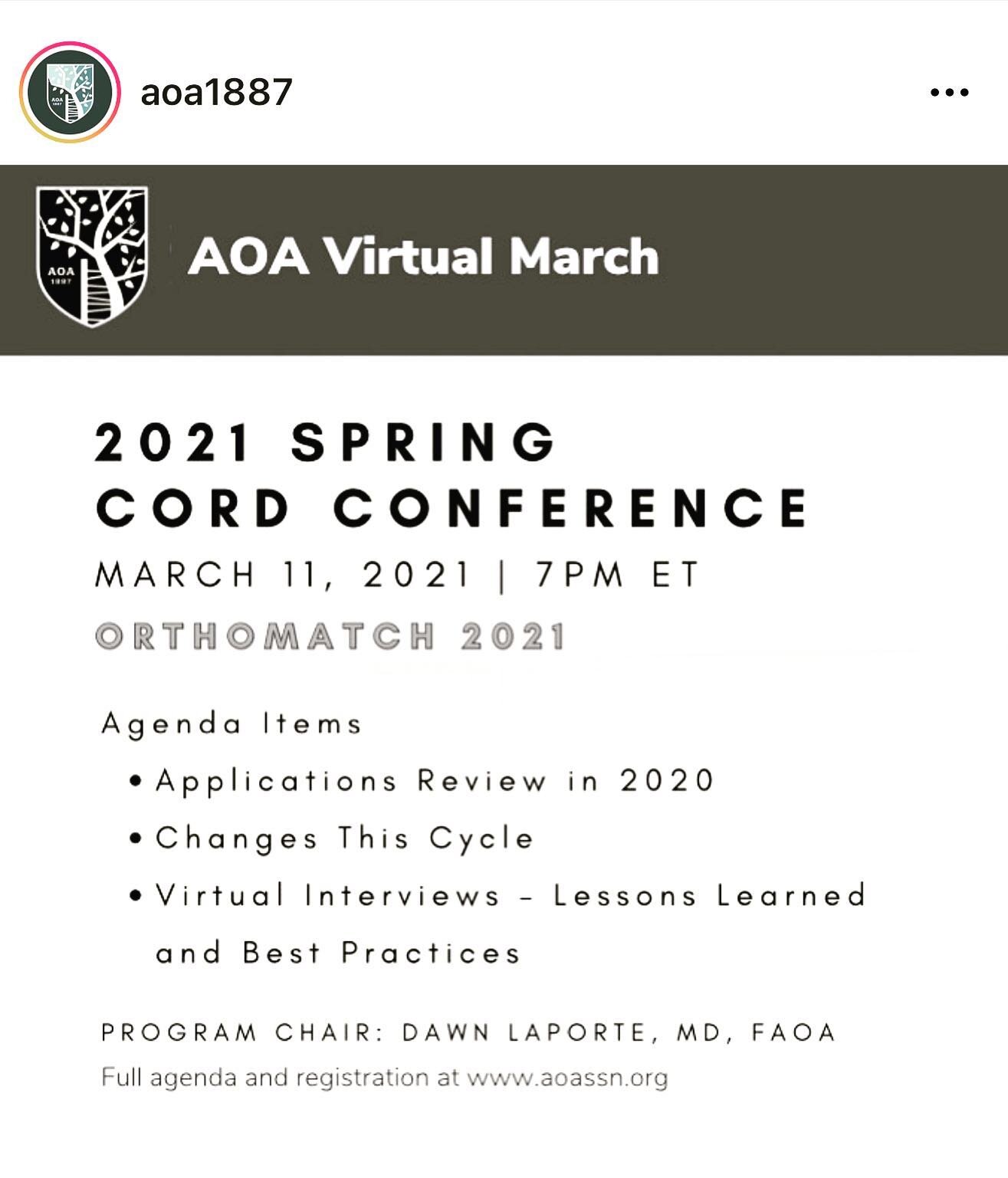
MiraSMART Conferencing offers a complete and cost-effective abstract and database management solution. We tailor and configure our robust platform to meet your organization’s unique needs. Our simple to use, intuitive user interface makes life easier for both the end-user and administrators.
Our Services
From the submission, to peer reviews, scheduling and beyond. The miraSMART Suite is comprised of several integrated software modules that may be utilized on a stand-alone basis or in combination.
The MirA Difference
Unique needs requires customized solutions. At Mira we provide tailored services, with unmatched project management but still at a fixed price.
MiraExpress
If you are planning a smaller conference and worry that our solutions may not be the right fit MiraExpress may be just what you need.

Simple and Clear Submission
MiraSMART allows you to easily customize the abstract/paper/poster submission process. Your authors and presenters will love the resulting simple and clear process.

Our History
Our founder, Jim McKelvey, says that people who solve problems are the happiest people. If that’s the case, we’re surely the happiest people around.
Follow MIRA on Social Media